Building a router with Linux is a viable alternative to commercial products in many applications. In this article, we explore the process of optimising Linux for the best packet-forwarding performance by exploiting symmetric multiprocessing (SMP) and Ethernet interfaces with multiple queues. We take advantage of the Linux kernel features known as Receive Packet Steering (RPS), Transmit Packet Steering (XPS), and IRQ affinity.
Queues, IRQs, and CPUs
The lessons in this article should apply to a variety of server-class network interfaces, but for our router platform we chose a battery of Intel I350-series interfaces. These are supported by the igb driver in Linux, which is produced by Intel itself and has a reputation as a good performer. More importantly, each I350 interface presents up to 8 send queues and 8 receive queues to the system, which will help us distribute network processing load over multiple CPUs.
The I350 implements its own hashing logic, such that (on the receive side) packets which are part of the same flow should be consistently delivered via the same queue. On the send side, it is the responsibility of the network stack to do the same thing. By establishing this flow/queue affinity, binding queues to different CPUs allows one to achieve flow/CPU affinity. That pays performance dividends because it creates ultimately an affinity between network flows and CPU caches, taking pressure off of each cache. Since each queue (or queue pair in some cases) is also associated with a hardware IRQ, handling of these IRQs can likewise be distributed across CPUs.
The igb driver intelligently reduces the number of queues per interface-direction to the number of logical CPUs. The reasoning for this reduction is that each queue entails some overhead, and there is no advantage in maintaining more queues than there are CPUs. In our test system, we have a single 6-core Xeon CPU which supports hyper-threading, presenting 12 logical CPUs by default. Since there are only 6 physical L1 caches on this chip, and our purpose is to create affinity between network flows and CPU caches, we disabled hyper-threading. This left us with 6 logical CPUs and 6 matching queues for each direction (send and receive) of each network interface.
How to control affinity
The Linux features known as Receive Packet Steering (RPS), Transmit Packet Steering (XPS), and IRQ affinity, allow us to control the affinities between CPUs and network queues/interrupts. Each of these can be controlled through nodes in the Linux pseudo-filesystems, by reading and writing bitmaps (as hexadecimal numbers) representing CPU assignments.
Let's start with RPS for receive queue 0 on eth1. The relevant node is /sys/class/net/eth1/queues/rx-0/rps_cpus. In this path, eth1 is the name of the network interface, rx-0 designates receive queue 0, and rps indicates RPS of course. For XPS on the equivalent sending queue, rx-0 would become tx-0, and rps would become xps. To show the available queues for eth1, you would simply list the files in /sys/class/net/eth1/queues.
Moving on to IRQ affinity, the relevant nodes are /proc/irq/*/smp_affinity where the * is the (hardware) IRQ number. You can discover your hardware IRQ assignments by reading /proc/interrupts. In some cases, send and receive queues are paired up to halve the number of IRQ assignments. Regardless, our concern is to control CPU affinity for the network queues, not the main network device. The queues are intuitively named and easy to identify in /proc/interrupts output. For unpaired queues, they will appear similar to eth1-rx-0 and eth1-tx-0, while paired queues will appear like eth1-TxRx-0.
The RPS, XPS, and IRQ affinity nodes all behave similarly. They will accept a write of a single hexadecimal value, or return one on read, representing the bitmap of CPUs assigned to the IRQ or network queue. The value "0" is the default, the meaning of which varies depending upon the kernel version (as we'll discover later). On our test router, with 6 CPUs, the potential values for writing to these control nodes range from binary 000000 to binary 111111. The rightmost (least significant) bit refers to CPU #0. So for example, to assign only CPU #5, we would write the binary value 100000 in its hexadecimal form 20 to the relevant node.
Experimental narrative
Our experimental configuration consisted of 3 active network interfaces on the router. Two of these interfaces (eth1, eth2) were connected to a dedicated packet generator, producing IP packets with randomised source addresses spanning a /8 (2^24 addresses) and destinations spanning a /24 (2^8 addresses). The remaining interface (eth3) was connected to another interface merely to provide layer-1 link presence. Packet forwarding was enabled on these three interfaces, and packets injected into eth1/eth2 were routed out via eth3 by virtue of a single routing table entry. The target of all output packets was a non-existent gateway (with a static MAC address assignment in the local ARP table) in order to eliminate any undue influence from a real layer-2 receiver from our measurements. We developed a tool called ifstat2 to allow us to measure and observe per-second forwarding performance, in terms of both packets and bytes, across interfaces in real time.
We began with the 3.2.39-2 kernel distributed by the Debian project. By default, this kernel placed all network load on CPU #0, resulting in poor forwarding performance and packet loss starting at about 558 Kpackets/second. At 1.6 Mpackets/second input, packet loss reached 20%. We thus experimented with different arrangements of CPU-IRQ-queue affinity. Distributing network load across all 6 CPUs produced the best packet forwarding performance, and eliminated packet loss:
| cpu0 | cpu1 | cpu2 | cpu3 | cpu4 | cpu5 | |
|---|---|---|---|---|---|---|
| TxRx-0 | × | · | · | · | · | · |
| TxRx-1 | · | × | · | · | · | · |
| TxRx-2 | · | · | × | · | · | · |
| TxRx-3 | · | · | · | × | · | · |
| TxRx-4 | · | · | · | · | × | · |
| TxRx-5 | · | · | · | · | · | × |
However this configuration took an extremely heavy toll on userland performance, including high latency in terminal sessions not due to network congestion. Distributing the network load to only 5 of the 6 CPUs alleviated the userland performance issue, but left the question of how to handle the remaining #6 queue of each interface-direction.
Intel's official igb driver supports reducing the number of queues with the RSS parameter at module loading time. However the igb driver present in the official Linux kernel does not include any of Intel's tuning parameters. Therefore we implemented an equivalent parameter in the driver ourselves, to allow us to reduce the number of queues to 5 and assign them as follows:
| cpu0 | cpu1 | cpu2 | cpu3 | cpu4 | cpu5 | |
|---|---|---|---|---|---|---|
| TxRx-0 | · | × | · | · | · | · |
| TxRx-1 | · | · | × | · | · | · |
| TxRx-2 | · | · | · | × | · | · |
| TxRx-3 | · | · | · | · | × | · |
| TxRx-4 | · | · | · | · | · | × |
Userland performance improved dramatically with the freeing of CPU #0. However another problem we recognised was the performance of the Linux routing cache (also known as the destination [dst] cache, or the routing information base [rib]). We noticed that this cache can easily fill up when a large number of endpoint addresses appear in packets flowing through the system, producing the tell-tale dst cache overflow kernel message. The cache also didn't seem to contribute consistently to performance, compared with ordinary routing table lookups.
We learned that Linux 3.8 has deprecated and removed the routing cache for just these reasons, so we continued our experiments using a Linux 3.8 kernel. Under the vanilla Linux 3.8.5 kernel, the affinity between CPUs and network IRQs was improved by default. We noted the following somewhat strange layout by inspecting /proc/interrupts:
| cpu0 | cpu1 | cpu2 | cpu3 | cpu4 | cpu5 | |
|---|---|---|---|---|---|---|
| eth1-TxRx-0 | · | × | · | · | · | · |
| eth1-TxRx-1 | · | · | × | · | · | · |
| eth1-TxRx-2 | · | · | × | · | · | · |
| eth1-TxRx-3 | · | · | · | × | · | · |
| eth1-TxRx-4 | · | · | · | × | · | · |
| eth1-TxRx-5 | · | · | · | · | × | · |
| eth2-TxRx-0 | · | · | · | · | · | × |
| eth2-TxRx-1 | × | · | · | · | · | · |
| eth2-TxRx-2 | × | · | · | · | · | · |
| eth2-TxRx-3 | × | · | · | · | · | · |
| eth2-TxRx-4 | · | × | · | · | · | · |
| eth2-TxRx-5 | · | · | × | · | · | · |
| eth3-TxRx-0 | · | · | · | × | · | · |
| eth3-TxRx-1 | · | · | · | · | × | · |
| eth3-TxRx-2 | · | · | · | · | × | · |
| eth3-TxRx-3 | · | · | · | · | · | × |
| eth3-TxRx-4 | · | · | · | · | · | × |
| eth3-TxRx-5 | × | · | · | · | · | · |
Substituting the 3.8.5-201.fc18 kernel distributed with Fedora 18, we observed a more sensible default layout, identical on each network interface:
| cpu0 | cpu1 | cpu2 | cpu3 | cpu4 | cpu5 | |
|---|---|---|---|---|---|---|
| TxRx-0 | · | × | · | · | · | · |
| TxRx-1 | · | · | × | · | · | · |
| TxRx-2 | · | · | · | × | · | · |
| TxRx-3 | · | · | · | · | × | · |
| TxRx-4 | · | · | · | · | · | × |
| TxRx-5 | × | · | · | · | · | · |
These tables show us the CPU/IRQ affinity, but not necessarily the CPU/queue affinity. Since the sysfs nodes for CPU/queue affinity (RPS and XPS) all showed their default value, and observing CPU utilisation under network load showed a balanced utilisation, it seems that the default CPU/queue affinity under 3.8.5 is probably similar or identical to the CPU/IRQ affinities shown above.
Despite these new defaults producing good packet forwarding performance, we did not want to set ourselves at the mercy of changing defaults in the future. For this reason, we continued to set CPU/IRQ/queue affinity ourselves. Unlike with Linux 3.2, distributing network load across all (6) CPUs in Linux 3.8 apparently does not bog down userland performance, so we decided to continue with our original and highest-performing layout.
In this diagram, we show how the send queues, receive queues, and IRQ lines of interface eth1 are arranged in our final test configuration:

Each pair of send/receive queues is associated with a single IRQ (this was the choice of the igb driver). Each group of 1 send queue, 1 receive queue, and 1 IRQ is associated with 1 CPU. This diagram shows only eth1, but eth2 and eth3 were configured identically to this diagram, with only the actual IRQ numbers being different.
Achieved performance
Achieving gigabit "wire speed" routing was not difficult. With 1000-byte packets, routing 122.2 Kpackets/second totalling 976 Mbits/second was a breeze. But the overhead in routing was clearly packets/second, not bits/second, as each packet must have its destination address inspected, looked up in the routing table, etc. The speed at which this loop iterates inside the kernel, rather than internal I/O bandwidth, was the deciding factor in our packet forwarding performance.
Decreasing packet size to 500 bytes, a more typical average on the WAN side of our network, showed a slight decrease in throughput: 955.2 Mbits/second. At 250 bytes, throughput decreases further to 913.6 Mbits/second, and at 100 bytes, down to 808 Mbits/second, at which point the number of forwarded packets per second reached 1 million. With a packet size of 50 bytes, the forwarding rate reached 1.49 Mpackets/second, and throughput dropped to 690 Mbits/second. Routing throughput measured in packets/second seems to be capped at this level, the figures unchanging as packet size drops to a minuscule 20 bytes.
Conclusions
Distributing network load across CPUs using a combination of Receive Packet Steering (RPS), Transmit Packet Steering (XPS), and IRQ affinity, is an effective way to increase packet forwarding performance on a Linux router. Under Linux 3.2 these affinities must be configured by the administrator, and one CPU should be excluded in order to maintain good userland performance. Under Linux 3.8, these affinities are configured by default, however administrators should still configure them in order to have a handle on the state of the system. Unlike Linux 3.2, Linux 3.8 kernels maintain good userland performance even when all CPUs are handling network load. Hyper-threading creates an artificial layer of abstraction between physical CPU caches and and logical CPUs, which does not contribute to performance, and detracts from performance due to the maintenance of additional queues.
Finally, we visualise the forwarding throughput and packet loss of the router, as packet size decreases, before and after tuning. In the "untuned" router, all network processing was handled by CPU #0. In the "tuned" router, network processing across 6 queues per interface-direction was distributed across 6 CPU cores.
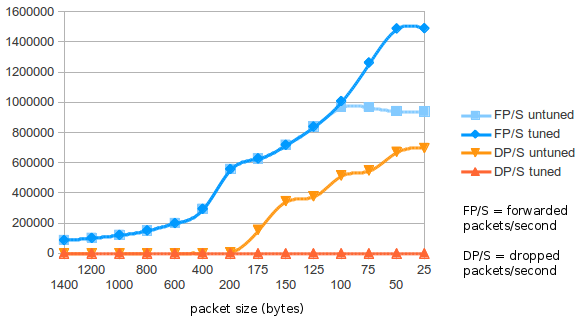
This research is limited by the 1Gbps capacity of output on eth2. Future research will include larger numbers of interfaces, especially in order to elucidate the tipping point where bits/second becomes the limiting factor over packets/second. In our current test configuration, this tipping point has obviously not been reached. Other potential performance bottlenecks may emerge with larger routing tables, larger number of interfaces, and other factors not yet explored.