We are proud to present our improved and more sustainable storage platform made with SSD drives and Ceph. As of today hosting at Greenhost will be faster, more resilient and scalable without downtime. It is the best new digital home for your websites, apps and projects.
The new storage platform is made with Solid State Drives and Ceph: a fault-tolerant open-source distributed peta-scale storage stack. That is a mouth full of technical terms we'd love to break down for you in this blog post.
-
Fault-tolerant: Ceph is self-healing. Any corruption of data will be detected and the damaged blocks will be replaced with healthy data from back-ups. Daily copies of all data are now replaced by live copies all day, every day.
-
Open-source: As with most technology we use, Ceph is Open Source. Any improvements we make will be delivered back to the community.
-
Distributed: The Ceph cluster is physically distributed and communicates over its own infrastructure outside the net. If one system experiences difficulties, other systems will take over.
-
Peta-scale: We can, in theory, store over one exa-byte of data. That is the same amount as all the internet traffic in 2004.
All data-storage will from now on take place on Solid State Drives. These drives are a lot faster than conventional drives and are very power efficient, thus reducing our energy usage.
The platform is available to all new contracts. Your existing sites will be migrated to the new platform in the coming weeks and no action is required from your side. You can check in the service centre if your webhosting is already using the new platform by looking for the 'SSD/Ceph' logo.
Tell me more!
We've began building the new cluster in 2014. Over the months we did plenty of performance and stress tests. It's been running like a charm for several months now. In April we concluded the testing phase and began preparation for mass deployment in May and June.
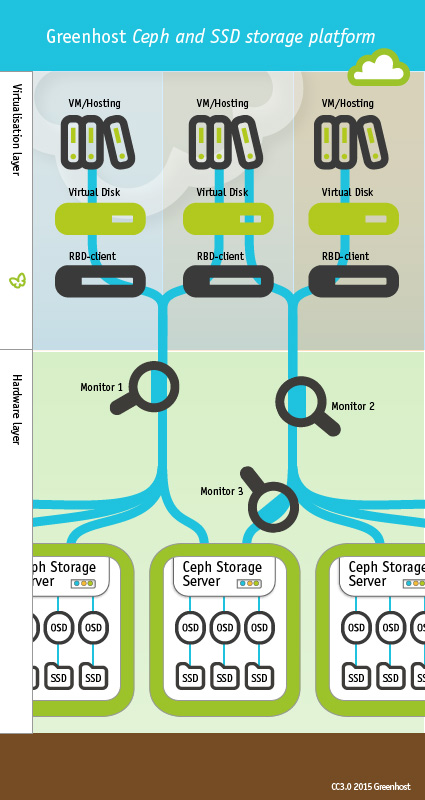
The basic building blocks of Ceph are the Ceph Storage Cluster and the Ceph Block Device.
Ceph Storage Cluster
The Ceph Storage Cluster is the foundation for all Ceph deployments. Based upon RADOS, Ceph Storage Clusters consist of two types of daemons: a Ceph OSD Daemon (OSD) stores data as objects on a storage node; and a Ceph Monitor (MON) maintains a master copy of the cluster map. A Ceph Storage Cluster may contain thousands of storage nodes. A minimal system will have at least one Ceph Monitor and two Ceph OSD Daemons for data replication. The Ceph Filesystem, Ceph Object Storage and Ceph Block Devices read data from and write data to the Ceph Storage Cluster.
Ceph provides an infinitely scalable Ceph storage cluster based upon RADOS. RADOS, the reliable autonomic distributed object store is a massively distributed, replicating, rack-aware object store. It organises storage in objects, where each object has an identifier, a payload, and a number of attributes.
Ceph's object storage system isn't limited to native binding or RESTful APIs. You can mount Ceph as a thinly provisioned block device. When you write data to Ceph using a block device, Ceph automatically stripes and replicates the data across the cluster. Ceph's RADOS Block Device is standard not available for Xen VM's. We developed our own tools to integrate RBD's transparent into our Xen platform.
Ceph Block Device
A block is a sequence of bytes (for example, a 512-byte block of data). Block-based storage interfaces are the most common way to store data with rotating media such as hard disks, CDs, floppy disks, and even traditional 9-track tape. The ubiquity of block device interfaces makes a virtual block device an ideal candidate to interact with a mass data storage system like Ceph. Ceph block devices are thin-provisioned, resizeable and store data striped over multiple OSDs in a Ceph cluster. Ceph block devices leverage RADOS capabilities such as snapshotting, replication and consistency. Ceph's RADOS Block Devices (RBD) interact with OSDs using kernel modules or the librbd library.
Objects are allocated to a Placement Group (PG), and each PG maps to one or several Object Storage Devices or OSDs. OSDs are managed by a user space daemon – everything server-side in Ceph is in user space – and locally map to a simple directory. For local storage, objects simply map to flat files, so OSDs don't need to muck around with local block storage. And they can take advantage of lots of useful features built into advanced files systems, like extended attributes, clones/reflinks, copy-on-write (with btrfs). Extra points for the effort to not reinvent wheels.
The entire object store uses a deterministic placement algorithm, CRUSH (Controlled Replication Under Scalable Hashing). There's never a central instance to ask on every access, instead, everything can work out where objects are. That means the store scales out seamlessly, and can expand and contract on the admin's whim.
Here is a nice schema to clear things up
Fun Fact
The name "Ceph" is a common nickname given to pet octopuses and derives from cephalopods, a class of molluscs, and ultimately from Ancient Greek κεφαλή (ke-pha-LEE), meaning "head" and πόδι (PO-dhi), meaning "leg". The name (emphasized by the logo) suggests the highly parallel behaviour of an octopus and was chosen to connect the file system with UCSC's mascot, a banana slug called "Sammy".